Memory Tuning in Oracle Database
by Rackspace Technology Staff
What is Memory Tuning?
Memory tuning distributes or reallocates the free memory to Oracle memory components. It is mainly used for performance tuning on Oracle queries. Nowadays, a major issue for every client is related to database performance. This blog explains how to tune memory in the database which results in high performance in databases.
The following are the various kinds of memory tuning methods that are available: OS-level process tuning, CPU tuning, RAM tuning, database tuning, etc. In this blog, I will be discussing the memory tuning in databases.
Database Memory Tuning:
Memory Tuning for the database is nothing but tuning the System Global Area (SGA). Following are the list of the major components w.r.t SGA tuning. Let’s look at each of these components in detail:
- Keep Pool
- Default Pool, Recycle Pool, Stream Pool
- DB Buffer Cache: Free buffers, modified buffers, pinned buffers
- Shared pool
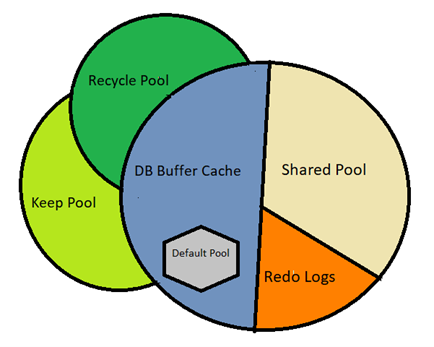
Keep Pool:
There are certain packages that are used daily. To increase the performance, you need to keep those packages in SGA. With the help of the procedure, you can keep that package in the keep pool.
If the space allocated to SGA is shut down, then SGA has to be reallocated to RAM, at that time even after keeping the package in the keep pool, it will be flushed off. Next time when you restart and execute that package, the package will remain in the keep pool until you shut down the database. By doing so we reduce the I/O's.
With the help of the hit rations, you can ensure that the parse code execution plans are flushing from the library cache. The hit ratio for library cache should be > 85%.
Stream Pool:
Is used to create a buffer for the data pump. Daily, certain tables (small tables) are used to increase the performance. It is better to keep those tables in the SGA (Keep pool). This will increase performance where you are not fetching the data from the disk but from the memory itself. For large tables, we have a recycling pool.
By default, whenever we select those tables (small tables) in the form of blocks is fetched in the data buffer cache and will be kept in the default pool. This default pool gets flushed off once you select other tables. If you have space in the buffer then it's fine, if not, then it will flush the previous tables to accommodate new tables. To increase the performance, keep small tables in the keep pool instead of _default pool_. The hit ratio for the data buffer cache should be > 95%. If it is less than 95% then we need to resize the database buffer cache.
The major part of memory tuning is the Database buffer cache and shared pool, which is useful for maintaining sufficient data in memory. Everyone needs to know the basic operations in the Database buffer cache for SGA tuning. At the end of the blog, I will share some sample SQL query examples to calculate the hit ratio to tune the memory.
### Free Buffers
Modified data use fetched blocks and copies to the data buffer cache before changing the image(data). These buffers are called Free Buffers.
From the below image, the disk having value 1000 or the memory having value 1000 are the same.
The below image shows the Free buffer:

Modified Buffers
Modified buffers are also referred to as Dirty Buffers. The image in the disk and the image in the data buffer cache of the data have been changed, but these buffers or data have not yet been written to the disk. These buffers are called Dirty Buffers.
The following image shows a modified buffer:

Pinned Buffers
The data in the DB buffer cache will change every time. The server process will select these modified data for further transactions. These selected data is nothing but pinned data or buffer
The data in the DB buffer cache will change every time. The server process will select these modified data for further transactions. These selected data are nothing but pinned data or buffers.
Physical reads: Oracle data blocks that Oracle reads from the disk by performing I/O.
Logical reads: If Oracle can satisfy a request by reading the data from the database buffer cache itself then it comes under logical reads.
DB block Gets: when Oracle finds the required data in the database buffer cache, Oracle checks whether the data is committed or not, if committed then fetches from buffers. These buffers are also known as DB buffer gets.
Consistent Reads: In the database buffer cache, the blocks that are present, are modified but not committed. Therefore, the data should be fetched from the undo datafile.

The goal of db_buffer_cache is to increase the logical reads
Soft Parsing: If we have an execution plan already available in Library Cache, it won’t go to the disk, it will create a parse plan (parse code) from the existing execution plan. This is called Soft Parse.
Hard Parsing: To create a parse code, it will check if any execution plan is available, if an execution plan is available then it goes with soft parse. If the execution plan is not available, then it performs a hard parse which means it goes to disk.
Shared Pool:: Shared Pool is a combination of Library Cache and Data Dictionary Cache.
Library Cache: The goal of Library Cache is to increase the soft parsing
Methods to achieve goal:
- Using bind variables
- By writing stored procedures
- Hit ratio (Should be > 85% if not increase the shared pool size)
- DBMS_Shared_pool (package)
Hit ratio plays a major role in tuning memory using SQL queries.
Data Dictionary Cache:
It is also called row cache. Data Dictionary Cache hit ratio must be >85%, if not increase the shared pool size.
Following are the Sample queries to calculate the hit ratio
.
`select (sum(pinhits)/sum(pins))*100 as lchitratio from v$librarycache;`
`select namespace, pins, pinhits, reloads from v$librarycache order by namespace;`
To get the package of dbms_Shared_pool please run `@$ORACLE_HOME/rdbms/admin/dbmspool.sql`
`select namespace, kept, locks, executions from v$db_object_cache where type like '%PROC%';`
Data Dictionary Cache hit ratio:
`select (sum(gets-getmisses-fixed))/sun(gets) as "ddchitratio" from v$rowcache;`
Redo log Buffer Cache
select name, value from `v$sysstat` where name like `'redo%';`
I hope you find the above-discussed points useful and can now easily tune memory in the database.

Recent Posts
Escalado de personalizaciones de zonas de aterrizaje en AWS
Mayo 1st, 2025
Informe sobre el estado de la nube en 2025
Enero 10th, 2025
Patrones de redes híbridas de Google Cloud - Parte 2
Octubre 16th, 2024
Patrones de redes híbridas de Google Cloud - Parte 2
Octubre 15th, 2024