EC2 Auto Scaling Lifecycle hook? Not so fast…
by Michael Bordash, Principal Cloud Practice Architect /Jake Skipper, Cloud Practice Architect, Rackspace Technology
Amazon EC2 Auto Scaling lifecycle hooks are powerful mechanisms providing the ability for your architecture to respond to Auto Scaling events. A common use case for lifecycle hooks is sending notifications to an Amazon EventBridge which in turn can invoke serverless functions. For more information, checkout this AWS tutorial located here. Event-driven functions are extremely flexible, but they are not always the optimal choice depending on the use case.
Amazon Lambda is a great choice for executing custom logic, commonly written in Python, Go or Node.js to name a few popular choices. These languages can leverage an AWS SDK, such as Boto3, to easily interact with other AWS services like DynamoDB or S3. Although Lambda is extremely powerful, a solution involving additional complexity and requiring additional maintenance may not be necessary in all situations. There is another way to execute custom actions leveraging the underlying operating system.
Below I’ll describe a scenario our team recently ran into where we were able to execute a process to complete a specific action during a shutdown event without the need for any additional AWS services. In our example, the EC2 instances in the Auto Scaling Group hosted a legacy Java EE based application. Not an ideal cloud-native platform to start off with but we did have a supported command-line scripting environment that we could leverage to manage the environment. The scripting language supports Java but requires a full J2EE runtime that is not practical to package up in a Lambda function and would add unnecessary complexity to the solution.
If you are not familiar with traditional application server topologies, there is typically an administration server that manages application servers which can belong to clusters. These managed servers can use the native scripting language to communicate with the administration server. Therefore, as a managed server instance is created or destroyed during a scaling activity, we can leverage these scripts to perform actions such as registering/deregistering itself from the cluster in which it belongs.
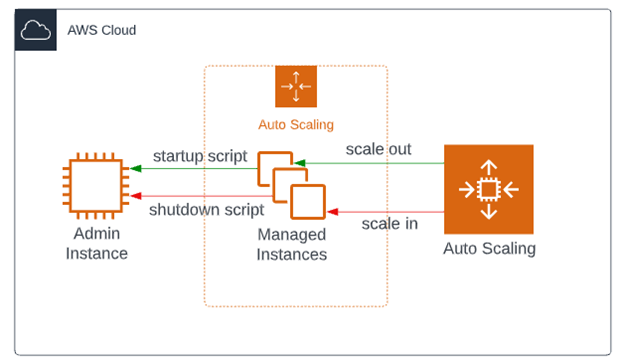
Figure 1. Example architecture diagram
Registering a new managed server when an EC2 instance launches it rather straightforward. Leveraging EC2 user-data, which is automatically executed during the launch process, we can execute the scripts to perform the necessary actions. But when an EC2 instance is terminated, there is no such mechanism we can rely on to “clean up” the resources that are about to be obsolete. As mentioned earlier, we could use a lifecycle hook that is triggered during the EC2 termination event which in turn could invoke a Lambda function to complete the necessary actions. Our current architecture does not leverage AWS EventBridge or Lambda so adding more resources to develop and maintain is not ideal. What if there is a simpler solution?
We decided to experiment with leveraging our own custom Linux service with systemd to perform the clean-up script execution. This is a simpler solution and allowed for us to leverage some key features of systemd to ensure all dependencies were maintained for successful script execution. Let us dive into this a bit more.
A custom AMI is created with all required software and scripts, allowing for an immutable artifact that we can version and track. During the Packer build process, we define and register the custom systemd service.
Here is an example Packer shell provisioner to install the service:

The custom systemd service used is like the example defined below.

Let’s break down the service configuration.
Type – A oneshot type is ideal for a process that is intended to perform an action and then fall back to being inactive.
RemainAfterExit - In this case, we only wanted to do something on system shutdown, so we used /bin/true as our ExecStart command. This command runs and immediately exits successfully. RemainAfterExit tells the service to still consider itself in a “running” state, despite the ExecStart program being finished. This way, ExecStop will be issued when system goes down or someone manually issues a stop on this service. This is useful for a “service” that is just two scripts.
RequiresMountsFor – This is critical to ensure that the mounted directories are available for the shutdown script. Some of these are NFS mount points and we must ensure that during shutdown, the NFS service is not unmounting these volumes before our service completes executing against the shared filesystem.
ExecStop – This defines the script that will be executed to perform our custom actions.
ExecStart - Can be used for performing actions on startup. We opted to use instance user data but this is another option if you choose.
WantedBy – By specifying a particular systemd target here, we can choose when systemd should start this service. Multi-user target is typically the destination target for server Linux installs, so this lets systemd know we require this service to be running before the system is considered fully started. This will also order when the service should be stopped (e.g. shutting down, leaving multi-user.target). For a more in-depth look at the systemd and all the available configuration options, see systemd.io.
Conclusion
In summary, leveraging custom services with systemd may be an efficient way to implement custom actions that your application requires during Auto Scaling activities. Lifecycle hooks combined with Lambda functions are extremely powerful and have their place in your cloud architecture, but they are not always necessary as we demonstrated in this example solution.
Use the Feedback tab to make any comments or ask questions. You can also start a conversation with us.

Recent Posts
From Cloud Adoption to Cloud Advantage in Healthcare
February 23rd, 2026
My Journey of Building a Terraform AI Agent — Automating Cloud Infrastructure with AI
October 31st, 2025
Amazon Bedrock AgentCore Preview: A Solutions Architect’s First Look at the New Agentic AI Platform
October 30th, 2025
Microsoft's 2025 Licensing Evolution: Transform Change into Opportunity
October 9th, 2025
7 Critical AWS Architecture Risks: How to Assess and Remediate Security Gaps
September 25th, 2025