Identify Long Running Jobs with Apache Airflow
by Rackspace Technology Staff
Apache Airflow is relatively a new, yet immensely popular tool, for scheduling workflows and automating tasks in a production environment.
With Airflow, one can create Directed Acyclic Graphs, commonly called DAGs, which are used for representing these workflows graphically. The underlying code is written in Python which relies on calling libraries for scheduling tasks periodically.
One of the common challenges with any job scheduler is to identify those workflows that run longer than their average run time. This is particularly important for the production team supporting day-to-day operations. The reason is that there is always a chance of missing that one nasty job out of the hundreds of jobs running in a live environment. This can even lead to a business SLA breach.
You can solve this issue by proactive monitoring.
Airflow Database Usage: Airflow jobs are tracked by underlying relational tables that maintain the log for all the DAGs, the tasks within each DAG, running statistics, running status, etc. to name a few. You can also query these tables using SQL statements available in the Data Profiler option in Airflow version 1.10.15+ under Ad-Hoc Query. In the later versions of Airflow, this Data Profiler is disabled.
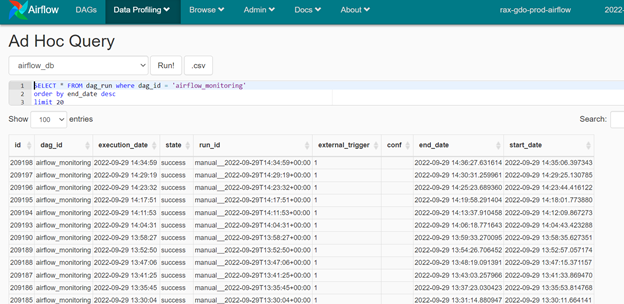
In the following example, the database is – airflow_db. It is using MySQL. Out of the tables, the table which is relevant is –dag_run

The snapshots give a view of all the DAGs that are currently running
The above output shows all the column information for DAG - airflow_monitoring
Therefore, I took the advantage of the above-mentioned “airflow_db” database that can help figure out DAGs that are running longer than their usual run time.
Eureka:
The basic idea is to execute a process in the background from these tables and figure out the DAGs in the execution state.
From such DAGs in execution, I compared the current run time to the average run time. If the current run time is more than the average run time by a considerable margin, then we have a DAG of interest which needs to be investigated. There’s a caveat here: the average run time for each DAG was previously calculated and stored in another manually created table.
This entire process is now encapsulated within a new DAG that monitors the environment in which it is deployed and executed in a regular manner. In this case, I have set it to run on an hourly basis.
Following are the two DAGs created for overcoming the above problem:
- load_data_from_airflow_to_bq – (Monthly dag Run)
- a. I’ve used the “airflow_db” database’s – “dag_run” table to get all the individual successful DAG run jobs in the past 30 days.
- b. Then, I ran the following MySQL query to get the average time of every running DAG
SELECT a.dag_id, avg(diff_time) FROM ( SELECT dag_id, start_date,end_date, TIMESTAMPDIFF(SECOND,start_date, end_date) as diff_time FROM dag_run WHERE state = "success" and start_date > NOW() - INTERVAL 30 DAY ORDER BY start_date desc ) a GROUP BY dag_id
- c. Then, I stored it in a list of lists to store average DAG run data.
- d. For the job to run, I’ve scheduled that job to run monthly, to get fresh average DAG run data for every month.
- e. The choice to revisit this process monthly keeps the Average Run Time information updated in a regular manner. This will maintain the historical run time of each DAG based on recent history based on a variety of factors such as code updates, the environment in which the DAG is running, etc.


load_data_from_airflow_to_bq DAG
- job_for_long_running_checks – (Every Hour DAG Run)
-
a. The above DAG will take advantage of the above average dag_run table from the GCP big query and will compare the DAG run with the current run time with all the individual DAGs. The steps involved include:
i. Using a big query client to connect to GCP and fetch the data of the average dag_run time and store it in a python dictionary.
ii. Query the “airflow_db” database’s – “dag_run” table to get all the running DAGs that are in
SELECT dag_id,start_date, TIMESTAMPDIFF(SECOND,start_date, NOW()) as diff_time FROM ( SELECT dag_id, max(start_date) as start_date FROM ( SELECT dag_id, start_date FROM dag_run WHERE state = "running" ORDER BY
-
iii. I’ve used the python dictionary data structure to take advantage of hashing that queries faster. -
iv. Once the data was available, I compared the Python “dictionary” datatype using the “for” loop to the average run time and the current run time. Then, I checked if the DAG name is matching or not. If the current run time was greater than the average run time, then the code was supposed to add that DAG name, its current run time, and its average run time to the new Python “list” datatype. I’ve stored this time value data in the format of “HH:MM:SS”. -
v. A point to note here, I have added a multiplying factor of 1.2 implying if the current time is 1.2 times more than the average run time, only then it makes sense to investigate further. This multiplying factor is something that opens to interpretation based on SLA, and business needs, among other interpretations.

vi. Once the data is available, we need to send a mail alert to the team, so to format the data in a readable format. Here we use the Jinja templates engine

vii. The following function will trigger a mail alert to us every hour to check if DAG is running more than the average time.

Job_for_long_running_checks DAG
TECHNOLOGY USED:
- Python
- Airflow
- GCP
CONCLUSION
This automation tool collects data efficiently, without affecting the server performance that hosts this tool. The tool has scheduled alerting and notification capabilities that can be easily customized based on the use case. The data collected is easy to understand and act upon which also has a hyperlink to the DAG linking to the hosted environment that is running longer than usual.

Recent Posts
From Cloud Adoption to Cloud Advantage in Healthcare
February 23rd, 2026
My Journey of Building a Terraform AI Agent — Automating Cloud Infrastructure with AI
October 31st, 2025
Amazon Bedrock AgentCore Preview: A Solutions Architect’s First Look at the New Agentic AI Platform
October 30th, 2025
Microsoft's 2025 Licensing Evolution: Transform Change into Opportunity
October 9th, 2025
7 Critical AWS Architecture Risks: How to Assess and Remediate Security Gaps
September 25th, 2025